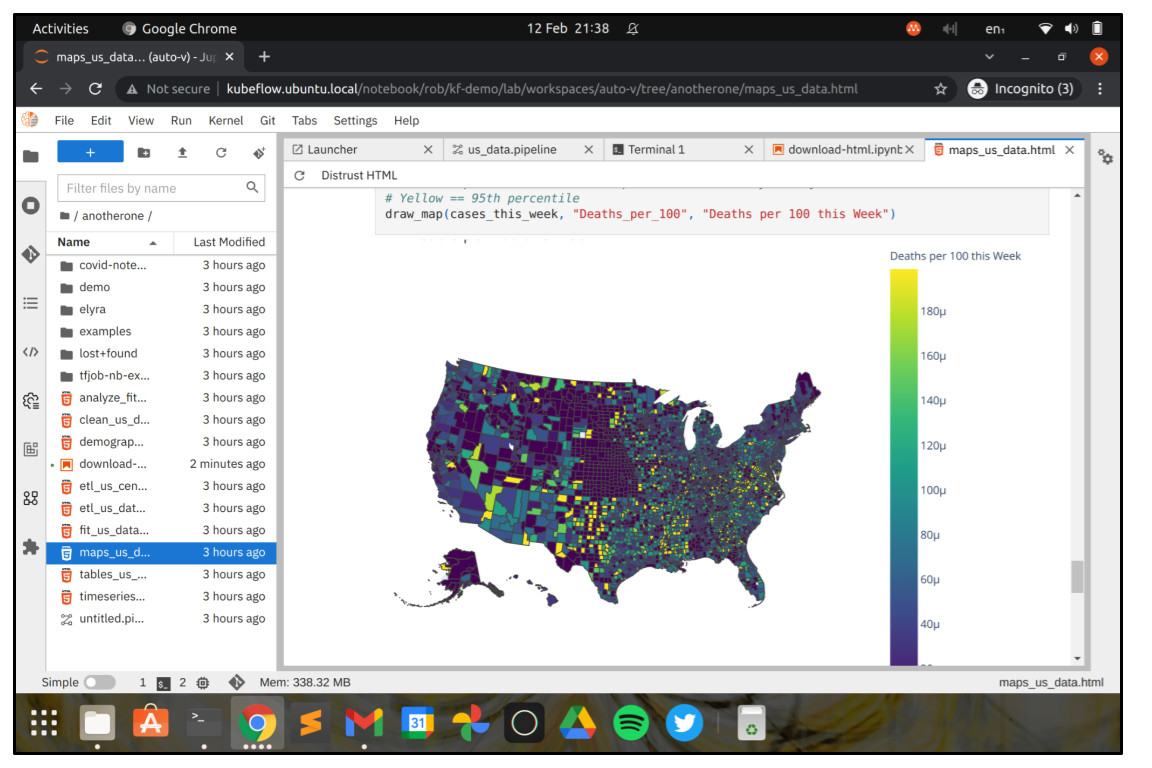
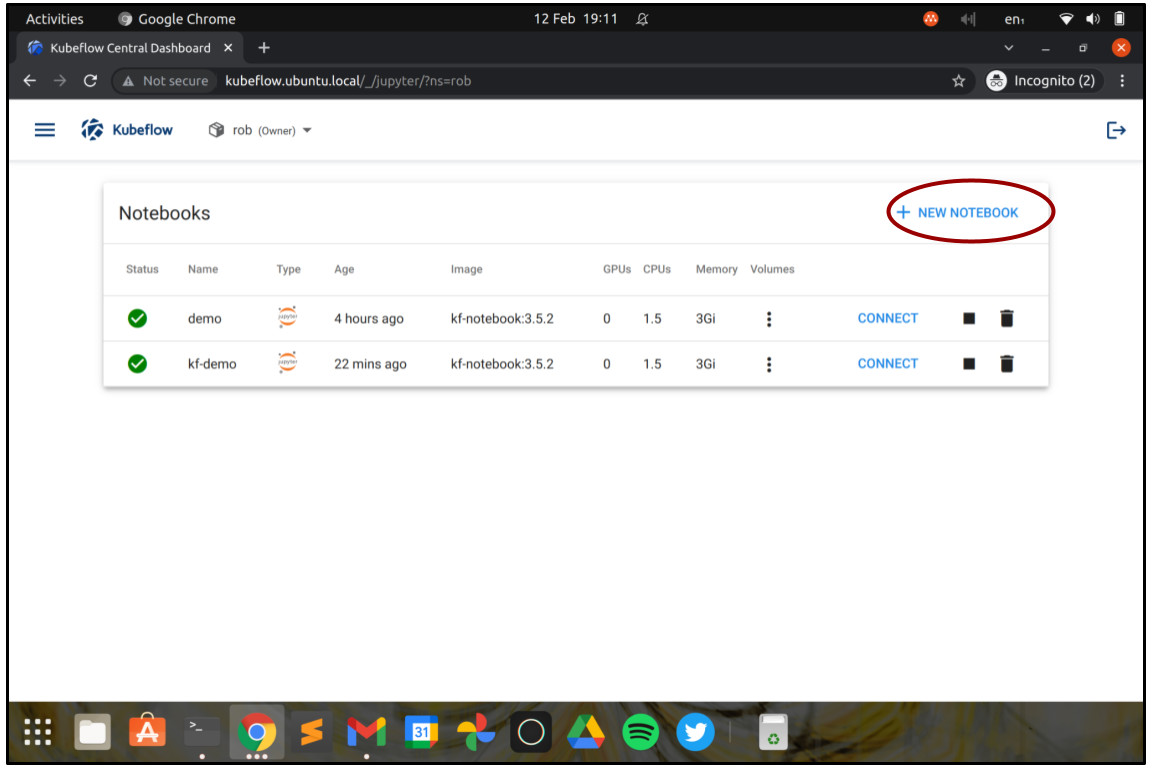
Let’s get started. From the Kubeflow Dashboard, choose Notebooks in the menu and click “Create a new Notebook”. JupyterLab notebooks are an incredibly powerful – yet easy to use, browser-based development environment for rapid software production, popular with data scientists.
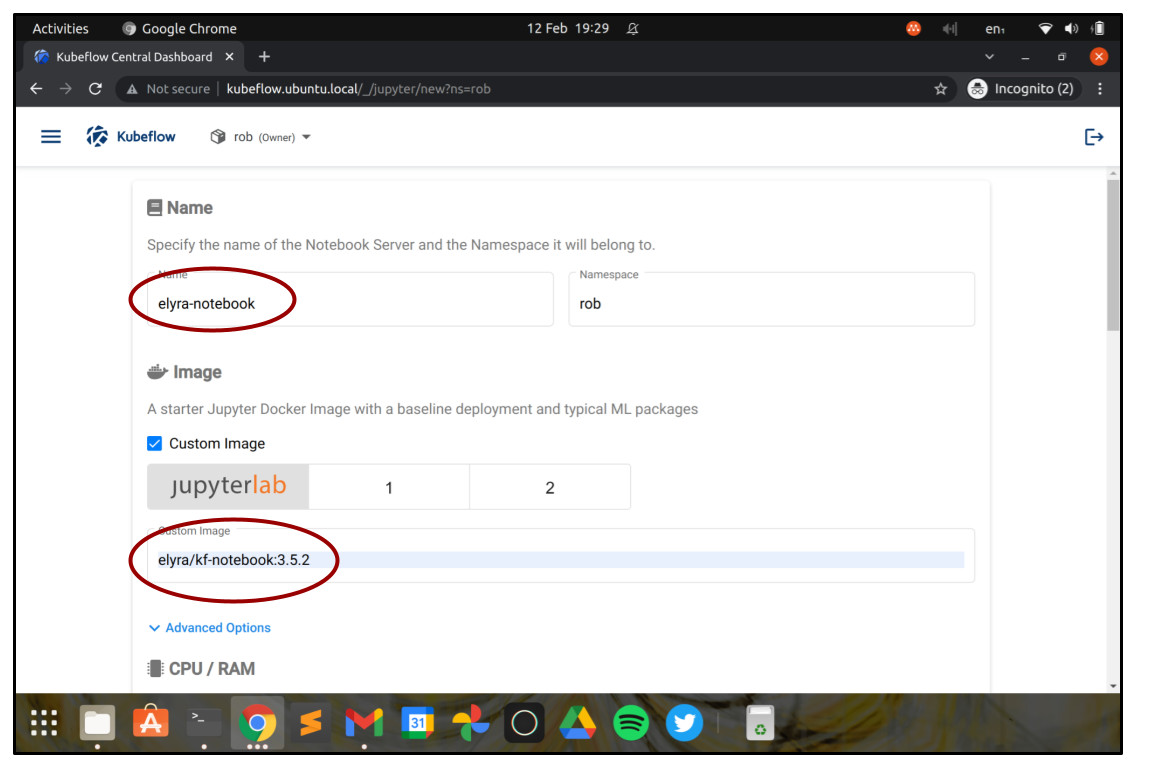
In the Create New Notebook screen, choose a Name for your Notebook Server, for example, “elyra-notebook”.
Check the checkbox “Choose custom image”, and enter the image name elyra/kf-notebook:3.5.2. This will launch the JupyterLab notebook environment with Elyra ready installed, so that we can use it right away for visual workflow design.
Leave the other sections with the default values for now, but know that you can use them to change things like the number of CPU cores, RAM, disks or GPUs available to the Notebook server. These values can be important when actively developing data science projects, but they’re not so critical to get started with Elyra, since the actual data science workload will be run as a batch on the Kubeflow Pipelines workflow engine.
Go ahead and click on Launch.
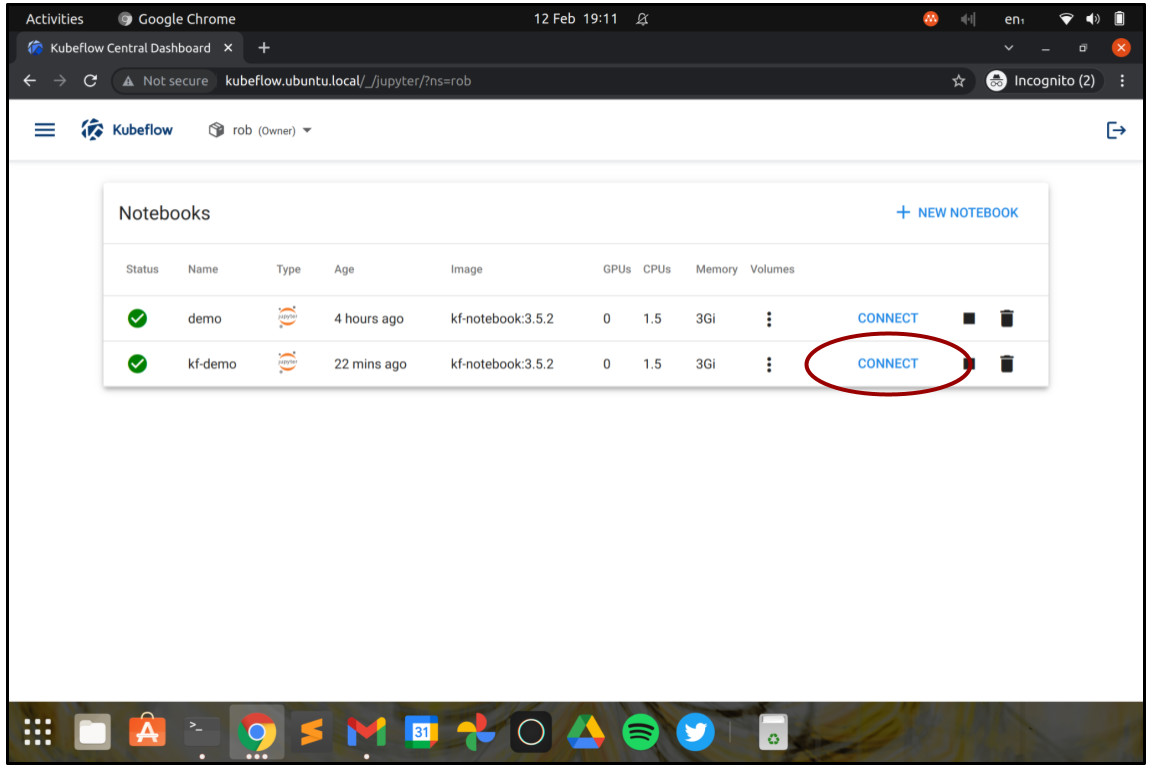
You should now return to the “Notebooks” screen and see your Notebook server starting up. Once the light turns green, you can connect to the Notebook server by clicking on the button marked “Connect”.
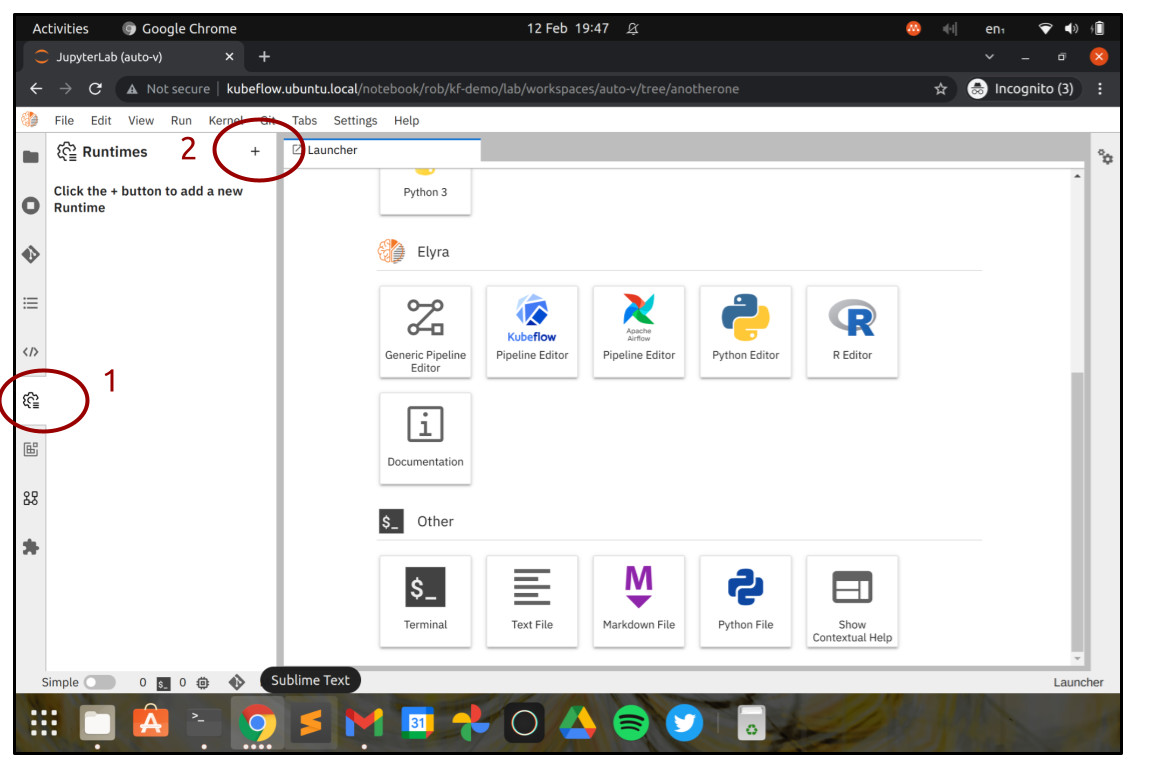
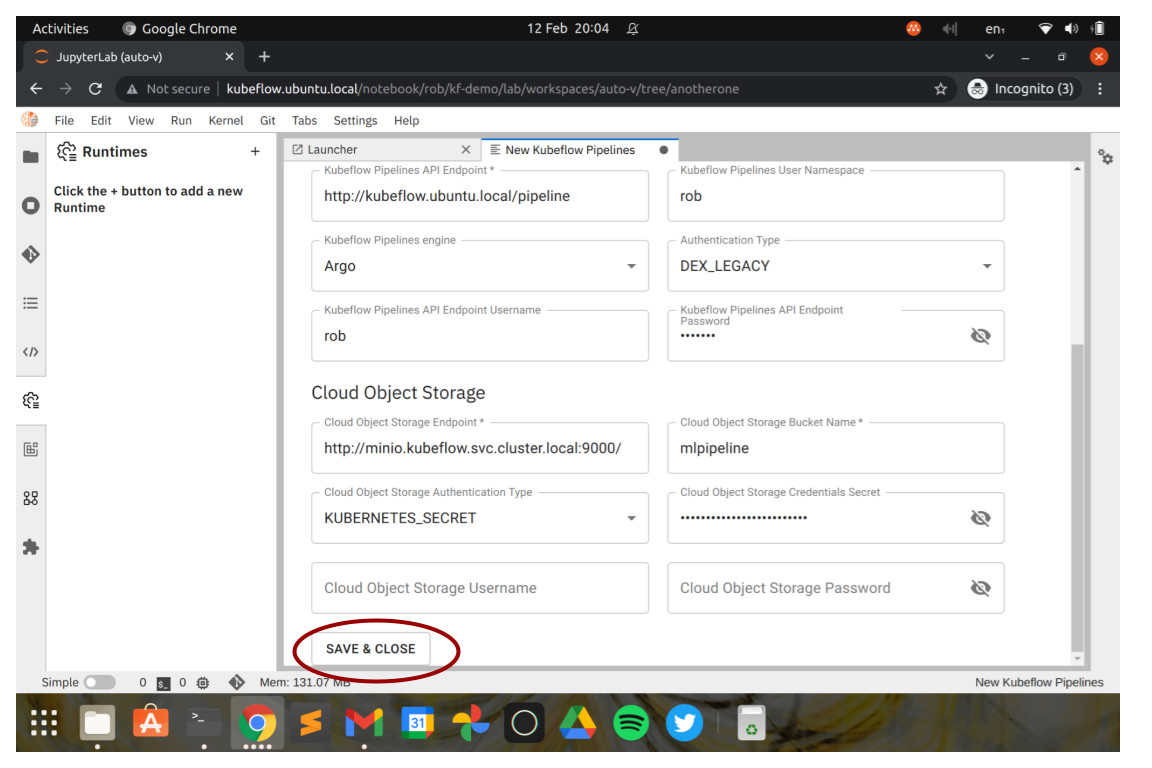
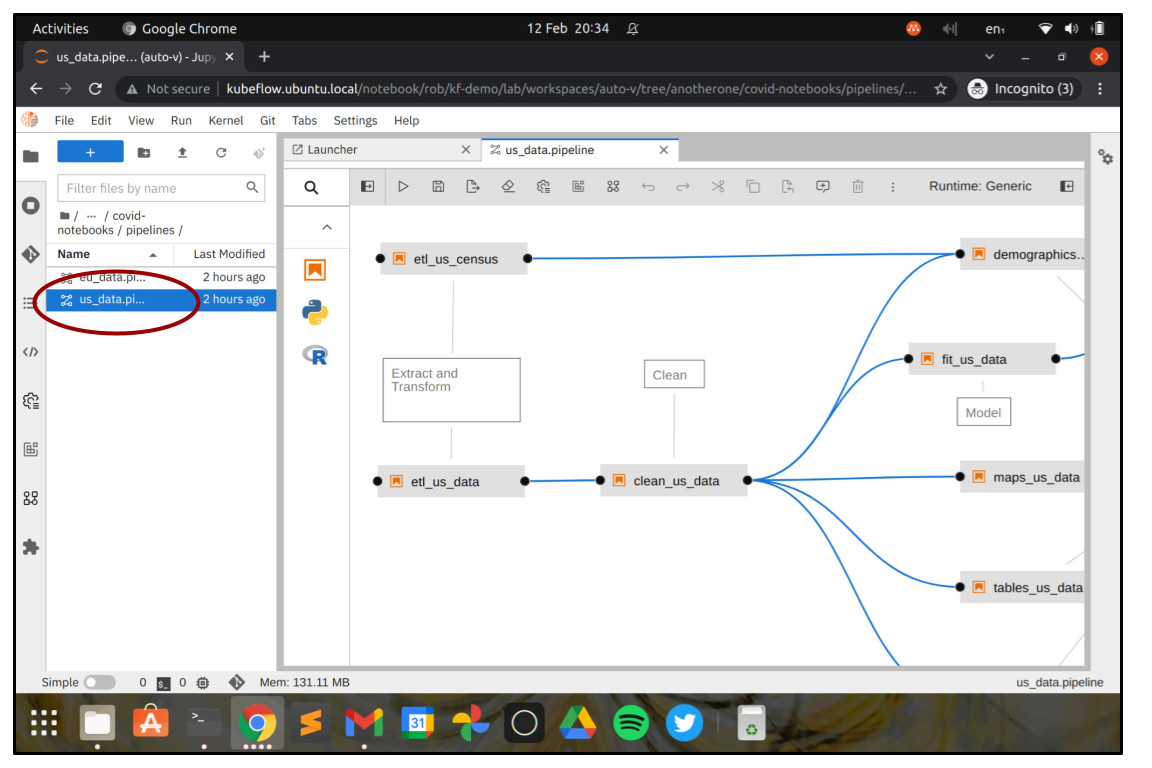
A new browser tab should appear, showing the JupyterLab launcher complete with Elyra workflow editor options. Congratulations so far!